- What Is Machine Learning?
- The 5 Main Types of Machine Learning
- Comparison Table: Types of Machine Learning at a Glance
- How to Choose the Right Type of Machine Learning for Your Project
- Ready to Implement the Right Machine Learning Approach?
- Frequently Asked Questions About Types of Machine Learning
- Which type of machine learning is best for beginners?
- How much data do I need for machine learning?
- Can I combine different types of machine learning?
- How long does it take to train a machine learning model?
- What programming languages are used for machine learning?
- How do I measure machine learning model performance?
Types of Machine Learning: How to Choose the Right Approach for Your Business


Every machine learning project starts with a choice that determines everything that follows. Pick the wrong type, and you’ll discover the mistake months later, when the model fails in production, the budget is gone, and competitors have already released similar solutions.
The problem isn’t a lack of information. There’s too much conflicting advice. Data scientists advocate the techniques they know best. Vendors insist their platform can solve every use case. Consultants often recommend approaches that worked in completely different environments. Meanwhile, you’re left trying to interpret whether supervised learning, unsupervised clustering, or reinforcement learning actually fits what you’re building.
This guide explains the five main types of machine learning, when each works, and how to match the right approach to your specific challenge. We’ve shared insights as a leading machine learning development agency to help you pick the ML approach that fit your needs, with practical examples that cut through the confusion.
What Is Machine Learning?
Before diving into different types of machine learning, let’s establish what machine learning actually means and why it matters for your business.
When people ask “what is machine learning?” or “what does ML mean?”, they’re asking about one of the most transformative technologies reshaping business operations today.
Machine learning is a subset of artificial intelligence that enables systems to learn from data and improve performance without explicit programming for every task. Instead of following rigid if-then rules coded by programmers, machine learning algorithms identify patterns, make predictions, and adapt based on experience.
This fundamental difference separates machine learning and artificial intelligence from traditional software development. Traditional programs follow instructions you write. Machine learning programs write their own instructions by learning from examples.
Now, let’s explore the five main ML models used for developing machine learning solutions.
The 5 Main Types of Machine Learning

Machine learning algorithms fall into five broad categories based on how they learn from data. Each represents a distinct approach to teaching machines, with different data requirements, computational costs, and ideal use cases. Understanding these five types of machine learning models is crucial for effective ML model selection and forms the foundation of modern AI applications across every industry.
1. Supervised machine learning
Supervised learning trains models on labeled datasets where both inputs and correct outputs are known. The algorithm learns by studying examples with answers, then applies this knowledge to make predictions on new data.
Think of it as learning with a teacher who provides the answer key. You show the system thousands of examples with correct labels, and it discovers the patterns connecting inputs to outputs.
This approach dominates production machine learning applications today because it delivers reliable, measurable results when you have historical data with known outcomes.
| Example: Training an email spam filter with 10,000 emails already labeled “spam” or “not spam.” The model learns what characteristics distinguish spam (suspicious links, certain keywords, unknown senders) from legitimate messages. Once trained, it classifies new emails automatically with high accuracy. |
Types of supervised learning
- Classification: Classification predicts categories. Is this email spam? Will this customer churn? Does this image contain a cat? The output is always a discrete class label, making it ideal for yes/no decisions and categorization tasks across business applications.
- Regression: Regression predicts numbers. What price will this house sell for? How many units will we sell next quarter? What’s the expected customer lifetime value? The output is a continuous value, perfect for forecasting and estimation problems.
How supervised learning works
Step 1: Data collection
Gather labeled training data relevant to your prediction task. For image recognition, collect thousands of images with correct labels. For sales forecasting, compile historical sales data with actual outcomes.
Step 2: Feature selection
Identify which input variables (features) matter most for predictions. In-house price prediction, relevant features include square footage, location, number of bedrooms, property age, and local school quality.
Step 3: Model training
The algorithm analyzes relationships between features and labels, adjusting internal parameters to minimize prediction errors through iterative mathematical optimization.
Step 4: Validation
Test the trained model on a separate validation dataset it never saw during training. This reveals whether the model learned genuine patterns or just memorized training examples.
Step 5: Deployment
Apply the validated model to new, unlabeled data in production. The model generates predictions based on patterns learned during training.
Step 6: Monitoring
Track model performance over time and retrain with new data as conditions change or accuracy degrades.
Real-world applications
- Healthcare: Diagnostic systems analyze medical images to detect cancer, pneumonia, or diabetic retinopathy with accuracy matching human radiologists, enabling earlier disease detection.
- Finance: Credit scoring algorithms evaluate loan applications by analyzing income, credit history, and payment patterns. Fraud detection systems flag suspicious transactions in milliseconds.
- eCommerce: Product recommendation engines analyze purchase history and browsing behavior to suggest relevant products, driving significant revenue increases through personalization.
- Security: Facial recognition systems authenticate users and monitor facilities. Email security filters block phishing attempts and malware before they reach inboxes.
- Autonomous Vehicles: Object detection algorithms identify pedestrians, vehicles, traffic signs, and road conditions in real-time, enabling safe navigation.
- Customer Service: Sentiment analysis classifies customer feedback as positive, negative, or neutral. Automated systems route support tickets to appropriate departments.
Pros & cons
| Pros | Cons |
| High accuracy when sufficient labeled data exists | Requires extensive labeled datasets (time-consuming and expensive) |
| Interpretable decision-making process in many algorithms | Struggles with patterns absent from training data |
| Well-established frameworks with proven track records | Risk of overfitting on training examples |
| Transfer learning enables model reuse across similar tasks | Labor-intensive data labeling process |
When to use supervised learning
- Historical data with known outcomes exists
- Clear input-output relationships define your problem
- Prediction accuracy is critical for your use case
- Sufficient budget for data labeling is available
2. Unsupervised machine learning
Unsupervised learning discovers hidden patterns and relationships in unlabeled data without predefined outcomes. Unlike supervised learning, where you provide correct answers, unsupervised algorithms explore data independently to identify structures and groupings humans might miss.
This approach excels at answering questions you didn’t know to ask. Instead of predicting “will this customer churn?” (supervised), unsupervised learning reveals “what natural customer groups exist in our data?” The algorithm finds patterns without being told what to look for.
| Example: Analyzing customer purchase behavior across 50,000 transactions without predefined segments. The algorithm discovers natural clusters: budget-conscious bulk buyers, premium quality seekers, impulse purchasers of trending items, and occasional gift shoppers. These insights emerge purely from purchasing patterns, revealing market segments for targeted campaigns. |
Three types of unsupervised learning
- Clustering: Groups similar data points together without predefined categories. Which customers behave alike? What patterns exist in this data? The algorithm discovers natural groupings, revealing segments you didn’t know existed for targeted strategies.
- Association: Finds relationships between variables. What products are purchased together? Which events co-occur frequently? These rules reveal hidden connections in transactional data, driving cross-selling strategies and bundle recommendations.
- Dimensionality Reduction: Compresses complex data while preserving essential information. It transforms thousands of variables into manageable dimensions, making visualization possible and speeding up processing without losing critical patterns.
How unsupervised learning works
Step 1: Data collection
Gather unlabeled raw data from your systems. No manual labeling required, making data collection faster and cheaper than supervised learning.
Step 2: Feature extraction
Identify which attributes matter for analysis. In customer segmentation, features might include purchase frequency, average order value, product categories, and browsing duration.
Step 3: Pattern discovery
The algorithm analyzes data to identify structures, groupings, and relationships using mathematical techniques like distance metrics and probability distributions.
Step 4: Interpretation
Humans analyze discovered patterns to determine if they’re meaningful or just mathematical artifacts. This step requires domain expertise.
Step 5: Validation
Assess whether discovered patterns make business sense and provide actionable insights.
Step 6: Action
Apply insights to business decisions such as customer segmentation, anomaly investigation, or data complexity reduction.
Real-world applications
- Marketing: Customer segmentation reveals natural groupings for targeted campaigns based on actual behavior patterns rather than assumptions, enabling tailored messaging and offers.
- Retail: Market basket analysis discovers which products customers buy together, driving store layout decisions, promotions, and bundling strategies.
- Security: Anomaly detection identifies unusual patterns indicating fraud, cyber threats, or system failures by learning what normal behavior looks like.
- Healthcare: Patient clustering groups individuals by treatment response patterns, disease progression, or genetic markers for more personalized medicine.
- Genomics: Pattern recognition in genetic data identifies markers associated with diseases or drug responses, handling massive dimensionality better than manual analysis.
- Image Processing: Image compression reduces file sizes while preserving visual quality, and feature extraction identifies important characteristics for analysis.
Pros & cons
| Advantages | Disadvantages |
| No labeled data required (cost-effective implementation) | Results can be ambiguous or difficult to interpret |
| Discovers hidden patterns humans might miss | No ground truth to validate accuracy objectively |
| Useful for exploratory data analysis | Requires domain expertise to determine if patterns are meaningful |
| Works well with large, complex datasets | Less precise than supervised learning for specific predictions |
When to use unsupervised learning
- Labeled data is unavailable or too expensive to create
- Exploring data to discover hidden patterns before hypothesis formation
- Customer segmentation without predefined groups
- Anomaly detection where normal behavior varies and evolves
3. Semi-supervised machine learning
Semi-supervised learning combines small amounts of labeled data with large volumes of unlabeled data. This hybrid approach leverages the guidance of labeled examples while learning from broader patterns in unlabeled data, bridging the gap between supervised and unsupervised machine learning methods. It emerged from a practical reality: labeling data is expensive, but unlabeled data is abundant.
Think of it as learning with a few teacher-checked examples, then practicing extensively on your own. The labeled data provides direction, ensuring the model learns correct concepts. The unlabeled data provides volume, helping the model generalize across diverse scenarios.
| Example: Building a medical diagnosis system with 500 labeled patient scans (expensive, requiring radiologist review) and 10,000 unlabeled scans (readily available from hospital archives). The labeled data guides the model toward correct diagnoses, while unlabeled data helps it learn the full diversity of disease presentations across different patients, imaging angles, and equipment. |
Common semi-supervised techniques
- Self-Training: The model labels its own confident predictions, then retrains on the expanded dataset. Simple but effective when the initial model quality is reasonable. This technique is commonly used in machine learning development projects where labeling budgets are constrained.
- Co-Training: Two models train on different feature sets (different views of the data), then label each other’s predictions. Each model’s perspective helps the other learn better patterns.
- Graph-Based Methods: These techniques propagate labels through data relationships, spreading information from labeled to unlabeled examples based on similarity. The algorithm builds a graph connecting similar data points, then flows label information across connections.
- Generative Adversarial Networks (GANs): GANs generate synthetic training data to improve learning, creating realistic examples that augment limited labeled datasets. One network generates fake examples while another learns to distinguish real from fake, pushing both to improve.
How semi-supervised learning works
Step 1: Initial training
Begin with whatever labeled examples you have, even if just hundreds instead of the thousands supervised learning typically requires.
Step 2: Prediction on unlabeled data
The partially trained model makes predictions on unlabeled examples, assigning confidence scores to each prediction.
Step 3: Pseudo-labeling
Predictions where the model is highly confident get treated as if they were human-labeled. These pseudo-labels augment the original labeled dataset.
Step 4: Model retraining
The algorithm retrains using both original human labels and high-confidence pseudo-labels, improving with each iteration.
Step 5: Iteration
Repeat this process multiple times. Each iteration expands labeled data and improves model accuracy.
Step 6: Validation
Test final model performance on a held-out test set to ensure quality meets requirements.
Real-world applications
- Natural Language Processing: Language translation with limited parallel texts, where obtaining translations for every sentence pair is resource-intensive, but unlabeled text is abundant.
- Medical Imaging: Disease detection with few annotated images, where expert radiologist labeling is expensive, but hospital image archives contain millions of unlabeled scans.
- Speech Recognition: Voice assistant training with limited transcribed audio, leveraging vast amounts of unlabeled speech data to improve accuracy.
- Web Content Classification: Categorizing articles with partial labels, using the structure of unlabeled documents to improve classification across categories.
- Autonomous Driving: Training perception systems with limited labeled sensor data, supplemented by enormous amounts of unlabeled driving footage.
- Drug Discovery: Molecular property prediction with limited experimental data, using unlabeled molecular structures to improve generalization.
Pros & cons
| Advantages | Disadvantages |
| Reduces labeling costs significantly compared to pure supervised learning | More complex to implement than pure supervised or unsupervised approaches |
| Better generalization than supervised learning with limited labels | Requires careful tuning of confidence thresholds and iteration parameters |
| Works effectively when labeled data is scarce, but unlabeled data is abundant | Wrong pseudo-labels can degrade performance if not managed properly |
| Improves model robustness across diverse scenarios | Still requires some labeled data to guide initial learning |
When to use semi-supervised learning
- Limited labeled data exists, but abundant unlabeled data is available
- Labeling is expensive, time-consuming, or requires scarce expertise
- Domain experts are scarce for manual data annotation
- Need better generalization than supervised learning with limited labels provides
4. Reinforcement machine learning
Reinforcement learning trains algorithms through trial and error, learning optimal actions by receiving rewards or penalties. The agent interacts with an environment, takes actions, and adjusts behavior based on feedback to maximize cumulative rewards over time. This type of machine learning differs fundamentally from supervised learning because there’s no dataset of correct answers upfront.
Think of it as learning to ride a bike. You try different balance adjustments and pedaling techniques, getting immediate feedback (staying upright or falling). Over time, you discover which actions lead to success through direct experience rather than following a manual.
| Example: Training a robot to navigate a warehouse. The robot tries different paths, receiving positive rewards for reaching destinations efficiently and negative rewards for collisions or delays. Over thousands of trials, it learns optimal navigation strategies without being explicitly programmed with routing rules. |
Common reinforcement learning algorithms
- Q-Learning: Learns the value of actions in specific states without requiring a model of the environment. The algorithm builds a table of state-action pairs, updating values based on rewards received.
- SARSA (State-Action-Reward-State-Action): Updates based on actual actions taken rather than optimal theoretical actions. More conservative than Q-Learning, considering the current policy’s behavior.
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks for complex state spaces. Handles high-dimensional inputs like images that traditional Q-Learning cannot process efficiently.
- Policy Gradient Methods: Directly optimize the policy function using gradient ascent. These types of machine learning algorithms are particularly effective when action spaces are continuous rather than discrete.
- Actor-Critic Methods: Combines value-based and policy-based approaches for more stable learning. One network (actor) decides actions while another (critic) evaluates them.
- Proximal Policy Optimization (PPO): Improves training stability through constrained policy updates. Currently, one of the most popular algorithms for robotics and game AI is due to its reliability.
How reinforcement learning works
Step 1: Environment setup
Define the environment where the agent operates, including possible states, available actions, and reward structure.
Step 2: Initial exploration
The agent begins taking random or semi-random actions to explore the environment and understand consequences.
Step 3: Reward collection
After each action, the environment provides feedback in the form of rewards (positive) or penalties (negative).
Step 4: Policy update
The agent updates its decision-making strategy (policy) based on which actions led to the highest cumulative rewards.
Step 5: Exploitation vs exploration
Balance between exploiting known good strategies and exploring new possibilities that might yield better results.
Step 6: Convergence
Continue training until the agent’s performance stabilizes at an optimal or acceptable level.
Real-world applications
- Autonomous Vehicles: Self-driving cars learn navigation and obstacle avoidance through simulated and real-world driving experience, optimizing for safety and efficiency. These machine learning solutions continuously improve through millions of miles of driving data.
- Robotics: Industrial robots optimize manufacturing processes, warehouse robots improve picking efficiency, and surgical robots enhance precision through continuous learning from each operation.
- Gaming: AlphaGo defeated world champions in Go, game AI creates challenging opponents, and NPCs adapt to player strategies in real-time, providing dynamic gameplay experiences.
- Finance: Algorithmic trading strategies optimize buy/sell decisions based on market conditions and portfolio performance, adapting to changing market dynamics.
- Healthcare: Treatment plan optimization learns ideal drug dosing schedules, and clinical decision support improves over time with patient outcomes data.
- Energy Management: HVAC systems optimize temperature control for comfort and efficiency, and power grids balance supply and demand dynamically, reducing waste and costs.
Pros & cons
| Advantages | Disadvantages |
| Learns optimal long-term strategies rather than immediate rewards | Computationally expensive requiring massive computing power |
| Handles sequential decision-making problems effectively | Training can be extremely time-consuming (weeks to months) |
| No labeled training data required | Requires careful reward function design to avoid unintended behaviors |
| Adapts to changing environments dynamically | Can be unstable during training with high variance |
When to use reinforcement learning
- Sequential decision-making problems with long-term consequences
- Optimal control and automation tasks in dynamic environments
- Game playing and competitive scenarios
- Robotics and autonomous systems requiring adaptive behavior
5. Self-supervised machine learning
Self-supervised learning generates its own supervisory signals from raw, unlabeled data. The model creates learning tasks by predicting parts of the input from other parts, eliminating the need for human labeling while achieving supervised learning-like performance.
This approach has revolutionized how we define machine learning in the modern AI era, particularly for foundation models. Rather than requiring expensive human labels, the data itself provides the supervision. The algorithm masks or transforms portions of data, then learns to reconstruct or predict the hidden information.
| Example: Training a language model by masking random words in sentences and having the model predict them. Given “The cat sat on the ___”, the model learns to predict “mat” or “floor” based on context. The text itself provides supervision without any human labeling effort. |
Common self-supervised techniques
- Natural Language Processing: Self-supervised NLP models learn language patterns by solving prediction tasks created from text itself
- Masked Language Modeling: Hide random words in sentences and predict them from context (used in BERT, GPT)
- Next Sentence Prediction: Determine whether two sentences naturally follow each other
- Contrastive Learning: Distinguish between similar and different text passages
2. Computer Vision: Image-based self-supervision creates tasks from visual data transformations:
- Image Rotation Prediction: Identify how much an image has been rotated (0°, 90°, 180°, 270°)
- Jigsaw Puzzles: Reconstruct scrambled image patches into correct positions
- Contrastive Learning: Learn what makes images visually similar or different
- Masked Image Modeling: Predict hidden regions in images from the surrounding context
3. Audio and Speech: Sound-based self-supervision learns from temporal audio patterns:
- Masked Audio Prediction: Reconstruct hidden segments in audio signals
- Contrastive Predictive Coding: Predict future audio frames from past context
How self-supervised learning works
Step 1: Data collection
Gather massive amounts of unlabeled data (text, images, audio, video) from available sources.
Step 2: Pretext task creation
Design tasks where one part of the data predicts another part. For text, mask words. For images, predict image rotations or reconstruct corrupted sections.
Step 3: Model pre-training
Train the model to solve these self-created tasks, learning useful representations of the data structure and patterns.
Step 4: Representation learning
The model develops internal representations capturing meaningful patterns, semantics, and relationships in the data.
Step 5: Transfer to downstream tasks
Apply the learned representations to specific tasks, often with minimal fine-tuning on small labeled datasets.
Step 6: Fine-tuning (Optional)
Adjust the pre-trained model for specific applications using limited labeled examples when available.
Real-world applications
- Large Language Models: BERT, GPT, and Claude trained on massive text corpora without manual labeling, enabling natural language understanding and generation.
- Computer Vision: Image recognition models pre-trained on billions of unlabeled images, then fine-tuned for specific tasks like medical imaging or satellite analysis.
- Speech Recognition: Audio processing systems learning from vast unlabeled speech data, improving transcription and voice understanding.
- Medical Imaging: Models learning from millions of unlabeled medical scans, then specializing for specific diagnostic tasks with minimal labeled examples.
- Autonomous Driving: Perception systems learning from extensive unlabeled driving footage, understanding road scenes and behaviors.
- Scientific Research: Protein structure prediction and molecular property learning from unlabeled biological and chemical data.
Pros and cons
| Advantages | Disadvantages |
| No manual labeling required (enormous cost savings) | Requires extremely large amounts of data to be effective |
| Scales to massive datasets effectively | Computationally intensive, requiring significant computing resources |
| Learns robust, transferable representations across tasks | May need task-specific fine-tuning for optimal performance |
| Enables foundation models serving multiple downstream applications | Less mature than traditional supervised learning approaches |
When to use self-supervised learning
- Massive unlabeled datasets are available in your domain
- Manual labeling is impossible or prohibitively expensive
- Building foundation models for multiple downstream tasks
- Pre-training before supervised fine-tuning on limited labeled data
With a clear understanding of how each machine learning type works, let’s compare them side-by-side to help you choose the right approach for your specific business challenge.
Need Help Choosing the Right Machine Learning Type for Your Project?
Consult with our machine learning experts to assess your project constraints, data resources, and success metrics for choosing the right machine learning implementation.
Comparison Table: Types of Machine Learning at a Glance
Understanding the differences between machine learning types helps you match the right approach to your business needs. This comparison highlights key characteristics, requirements, and ideal machine learning use cases for each type.
| Type | Data Requirements | Training Complexity | Accuracy | Best For |
| Supervised | Labeled datasets (thousands+ examples) | Medium | High | Prediction tasks with historical outcomes |
| Unsupervised | Unlabeled data only | Medium | Moderate | Pattern discovery and exploration |
| Semi-Supervised | Small labeled + large unlabeled | High | High | Limited labeling budget with abundant data |
| Reinforcement | Interaction data (rewards/penalties) | Very High | High (long-term) | Sequential decision-making and optimization |
| Self-Supervised | Massive unlabeled datasets | Very High | High | Foundation models and pre-training |
Key takeaways from the comparison
- For prediction accuracy: Supervised learning delivers the most reliable results when you have sufficient labeled data and clear success metrics.
- For cost efficiency: Unsupervised learning provides the lowest barrier to entry, requiring no labeling effort while still delivering valuable insights.
- For a balanced approach: Semi-supervised learning offers a middle ground, combining limited labeled data with abundant unlabeled data for improved performance.
- For long-term optimization: Reinforcement learning excels at complex decision-making where actions have delayed consequences and optimal strategies emerge through experience.
- For scalability: Self-supervised learning enables training on massive datasets without manual annotation, creating versatile models that transfer across multiple tasks.
The right choice depends on your specific situation. Data availability, budget constraints, accuracy requirements, and timeline all influence which machine learning frameworks and approaches work best for your project.
Comparing types is helpful, but how do you actually decide which one fits your specific project? Let’s walk through a practical decision framework that considers your real-world constraints and objectives.
How to Choose the Right Type of Machine Learning for Your Project
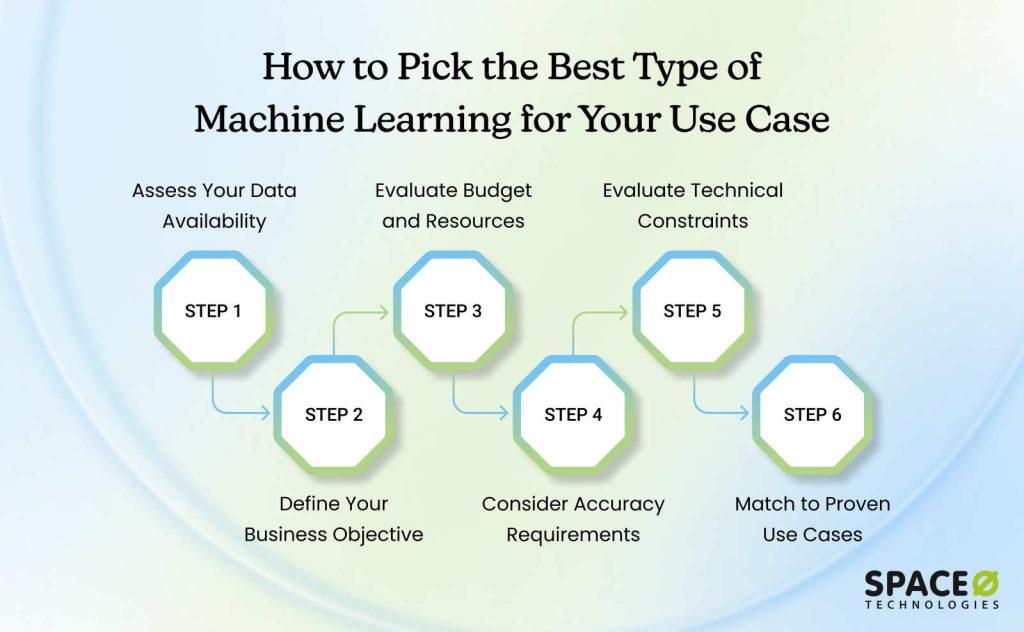
Selecting the appropriate machine learning type determines project success, budget efficiency, and timeline. The wrong choice wastes months of effort and thousands of dollars. This framework helps you match your specific situation to the right approach.
Step 1: Assess your data availability
Your data situation is the primary factor determining which machine learning type fits your needs. The amount, quality, and labeling status of your data directly influence which approaches are feasible and which will deliver the best results for your investment.
Action items
- Count how many labeled examples you currently have
- Estimate the cost and time required to label additional data
- Inventory total volume of unlabeled data available
- Assess data quality and completeness across all sources
- Determine if you can access interactive environments for feedback
Step 2: Define your business objective
What problem are you actually solving? Different objectives require different machine learning approaches. A clear problem definition prevents choosing sophisticated techniques when simpler methods would work better, saving time and reducing complexity throughout development.
Action items
- Specify exact output needed (category, number, grouping, or optimal action)
- Identify success metrics that define project completion
- Determine if this is prediction, optimization, or discovery
- Document the business impact of accurate vs. inaccurate results
- Clarify whether you need one-time insights or ongoing predictions
Step 3: Evaluate budget and resources
Machine learning implementation costs vary dramatically by type. Consider both upfront expenses and ongoing maintenance to avoid budget surprises midway through projects.
Resource constraints often eliminate certain approaches before technical evaluation begins, making this a critical early filter. Organizations often benefit from machine learning consulting services to accurately assess total project costs.
Action items
- Calculate the maximum budget for data labeling if needed
- Assess available computing infrastructure (cloud credits, GPUs)
- Evaluate team expertise in different machine learning approaches
- Determine a realistic timeline given business deadlines
- Identify whether ML development services support is required
Step 4: Consider accuracy requirements
How critical is prediction accuracy for your use case? What are the consequences if the model makes mistakes? High-stakes applications demand different approaches than exploratory projects, with corresponding differences in validation rigor, development time, and deployment safeguards required.
Action items
- Define the minimum acceptable accuracy threshold for launch
- Document consequences of false positives vs. false negatives
- Determine if interpretability is required for regulatory compliance
- Assess whether incremental improvement justifies additional cost
- Establish monitoring protocols for production performance tracking
Step 5: Evaluate technical constraints
Real-world constraints often eliminate certain options before technical evaluation begins. Infrastructure limitations, regulatory requirements, and deployment environments create hard boundaries that narrow viable approaches, helping focus efforts on solutions that can actually deploy successfully.
Action items
- Document computing power limitations (memory, processing capacity)
- Identify real-time processing requirements and latency limits
- Review data privacy regulations affecting your implementation
- Determine deployment environment (cloud, edge, on-premise)
- Assess need for model updates and retraining frequency
Step 6: Match to proven use cases
Learn from successful implementations in your industry by reviewing machine learning examples from similar organizations. Industry-specific patterns reveal which approaches consistently deliver results, helping you avoid experimental techniques where proven solutions exist and reducing project risk significantly.
Action items
- Research case studies from companies in your industry
- Identify which machine learning types they successfully deployed
- Evaluate whether your problem matches proven use cases
- Contact vendors or consultants for industry-specific guidance
- Join communities or forums discussing similar implementations
Choosing the right machine learning type means matching your constraints to the approach most likely to succeed. Start with data availability, align with business objectives, and validate against proven industry use cases.
Let Our ML Experts Handle Your Project
With 15+ years of ML engineering experience, we have the right capacity and expertise to build production-ready solutions using supervised, unsupervised, reinforcement, and self-supervised learning approaches.
Ready to Implement the Right Machine Learning Approach?
You’ve explored five distinct machine learning types, each solving different problems with varying data needs, costs, and accuracy levels. Success comes from aligning your business constraints with the approach that fits your specific situation rather than chasing the latest trends or most complex solutions.
Space-O Technologies brings 15+ years of ML expertise and 500+ successful projects across supervised, unsupervised, semi-supervised, reinforcement, and self-supervised learning implementations. As a trusted AI development company, we don’t just understand the theory behind these approaches. We’ve deployed them in production environments for startups, mid-sized companies, and Fortune 500 enterprises.
What sets us apart? We prioritize business outcomes over technical complexity. Our machine learning development services focus on delivering measurable ROI, not building impressive prototypes that collect dust. Check our portfolio to see how we’ve transformed AI challenges into working solutions across healthcare, finance, e-commerce, and manufacturing industries.
Google Ads Optimization Platform
Space-O transformed a Replit prototype into production-ready Google Ads optimization software. The platform automates campaign management using AI-powered recommendations for keyword optimization, bid adjustments, and budget allocation. Machine learning developers built intelligent suggestions that analyze performance data, reducing manual work from hours to minutes.
AI Headshot Generator App
We developed an iOS AI headshot generator app using Flux LoRA and Portrait Trainer models. The app creates personalized AI models from user photos in 2-3 minutes, then generates professional headshots in various styles within 30-40 seconds. Cloud GPU infrastructure enables scalable processing.
Canvas 8 – Figma to HTML Converter
Our team built Canvas 8, an AI-powered Figma-to-HTML converter using pre-trained models SigLIP and Australia/Mistral-7B-v0.1. The platform converts Figma designs into responsive HTML code within minutes, achieving 80% code accuracy. It accelerates the design-to-development process significantly for agencies and startups.
Ready to move forward? Schedule a free consultation with our machine learning specialists. We’ll evaluate your data, clarify your objectives, recommend the optimal approach, and create a proof-of-concept that validates feasibility before you commit to full-scale development.
Frequently Asked Questions About Types of Machine Learning
Which type of machine learning is best for beginners?
Supervised learning is most beginner-friendly due to clear objectives, abundant learning resources, well-established types of machine learning algorithms, and straightforward evaluation metrics. Classification tasks like spam detection or image recognition provide tangible results that help beginners understand core concepts.
Python libraries like scikit-learn make supervised learning accessible with minimal code, allowing newcomers to see results quickly and build confidence.
How much data do I need for machine learning?
Data requirements vary by the type of machine learning chosen. Supervised learning needs hundreds to thousands of labeled examples per class. Unsupervised learning works with smaller datasets.
Reinforcement learning requires millions of trials. Self-supervised learning needs massive unlabeled datasets. Data quality matters more than quantity. Clean, representative data delivers better results than vast amounts of noisy information.
Can I combine different types of machine learning?
Yes, hybrid approaches often deliver superior results. Semi-supervised learning combines supervised and unsupervised techniques when you have limited labeled data. Transfer learning uses self-supervised pre-training followed by supervised fine-tuning.
Many production systems employ ensemble machine learning methods combining multiple algorithms. Successful projects frequently start with unsupervised exploration, develop with semi-supervised learning, and deploy with supervised models.
How long does it take to train a machine learning model?
Training time varies dramatically by type and complexity. Simple supervised models train in minutes to hours. Complex deep learning models require days to weeks on GPUs. Reinforcement learning takes weeks to months due to its trial-and-error nature. Self-supervised foundation models train on massive compute clusters for weeks or months. Consider both training and data preparation time when planning projects.
What programming languages are used for machine learning?
Python dominates machine learning development with libraries like TensorFlow, PyTorch, and scikit-learn. R remains popular in statistics and academic research. Java and Scala serve enterprise big data environments through Apache Spark MLlib.
C++ handles performance-critical production systems. Julia is emerging for scientific computing. Python’s extensive ecosystem and community support make it the standard choice for most projects.
How do I measure machine learning model performance?
Performance metrics depend on the type and task. Classification uses accuracy, precision, recall, and F1-score. Regression relies on MAE, MSE, and R-squared. Unsupervised learning employs silhouette scores and domain-specific metrics.
Reinforcement learning tracks cumulative rewards. Always use validation datasets separate from training data to avoid overfitting and ensure realistic estimates before deployment.
Navigate ML Complexity With Experts
What to read next


