- How We Choose These 31 MLOps Tools
- Best MLOps Tools Comparison Matrix Based on Category
- Top 31 MLOps tools categories and best solutions
- MLOps Tools Investment Guide: Pricing and ROI Analysis
- 4 Latest MLOps trends and developments in 2025
- MLOps tools implementation roadmap and best practices
- Transform your ML operations with expert guidance
31 MLOps Tools To Enhance & Automate Machine Learning Processes


MLOps tools are specialized MLOps software platforms that automate and manage the complete machine learning development lifecycle, from data preparation to model deployment and monitoring. For enterprise AI teams, startups, and data scientists globally, these tools have become essential for creating automated workflows and enabling continuous monitoring.
According to Global Market Insights, the global MLOps market is experiencing explosive growth, projected to reach $39-89 billion by 2034, representing a massive leap from the current $1.7-3.0 billion in 2024. This represents a compound annual growth rate of 37.4-39.8%, driven by enterprises racing to deploy AI and machine learning at scale.
At Space-O, our 15+ years as a machine learning development company implementing MLOps solutions for 1,200+ clients across industries give us unique insights into which tools deliver real business value.
This comprehensive guide explores the best MLOps tools list available in 2025, providing an extensive list of MLOps tools that covers everything from open-source solutions to enterprise platforms, helping you make informed decisions for your AI initiatives.
How We Choose These 31 MLOps Tools
At Space-O Technologies, we evaluated 100+ MLOps platforms using these key criteria:
- Industry adoption – Tools with 10K+ GitHub stars or enterprise backing from AWS, Google, Microsoft, or established AI software development companies
- Production readiness – Solutions deployed successfully across our 1,200+ client projects
- Integration capabilities – Native support for TensorFlow, PyTorch, Kubernetes, and major cloud platforms as part of a comprehensive AI tech stack
- Cost-effectiveness – Balance between features and total ownership costs for different team sizes, similar to considerations in AI development cost planning
- Active development – Regular updates, responsive communities, and vendor roadmap alignment
- Real-world performance – Tools that consistently deliver ROI in healthcare, finance, and enterprise deployments
Best MLOps Tools Comparison Matrix Based on Category
Here’s a quick rundown of the top MLOps tools across different categories.
| Category | Best Open Source MLOps Tools | Best MLOps Tools for Enterprises | Best MLOps Tools for Startups | Best MLOps Tools for Business Growth |
|---|---|---|---|---|
| Data Management | DVC | Delta Lake | DVC | Pachyderm |
| Experiment Tracking | MLflow | Weights & Biases | MLflow | Neptune.ai |
| Feature Stores | Feast | Tecton | Feast | Hopsworks |
| Model Deployment | BentoML | Seldon Core | BentoML | Kubeflow |
| Model Monitoring | Evidently AI | Arize AI | Evidently AI | WhyLabs |
| Orchestration | Airflow | Prefect | Dagster | Kubeflow |
| LLMOps | LangChain | LangSmith | LangChain | Galileo |
| Vector Databases | Chroma | Pinecone | Chroma | Qdrant |
The choice between these tools depends on your specific requirements, team size, technical expertise, and budget constraints. MLOps open source tools offer maximum flexibility and cost-effectiveness, while enterprise solutions provide additional features, support, and scaling capabilities.
Now let’s explore each category in detail, examining the leading solutions and their unique strengths.
Top 31 MLOps tools categories and best solutions
Quick Answer: The best MLOps tools include MLflow for experiment tracking, Kubeflow for end-to-end pipelines, LangChain for LLMOps, and Pinecone for vector databases. Enterprise teams should consider Databricks or SageMaker, while startups can start with MLflow + DVC + Airflow for comprehensive coverage at minimal cost.
Data forms the foundation of every successful ML project, making robust data management and versioning tools essential.
Data management and versioning tools
What makes data versioning essential for MLOps? Data versioning forms the foundation of reproducible ML workflows. Without proper data management, teams struggle with inconsistent model performance, difficult debugging, and compliance issues.
1. DVC (Data Version Control) – Best Open Source
DVC leads the open-source data versioning space, offering Git-like operations for datasets and models. It integrates seamlessly with existing development workflows and supports all major cloud storage platforms (AWS S3, Google Cloud Storage, Azure Blob Storage). DVC is entirely free and has become the go-to choice for teams wanting to maintain dataset lineage without vendor lock-in.
Key Features:
- Git-like version control for datasets and models
- Integration with all major cloud storage platforms
- Experiment tracking and pipeline management
- Completely free and open-source
Best for: Teams wanting dataset lineage without vendor lock-in
2. Delta Lake – Best for Big Data
Delta Lake provides ACID transactions for big data workloads, enabling reliable data lakes with time-travel capabilities. Built on Apache Spark, it handles massive datasets with guaranteed consistency and supports real-time streaming ingestion. Delta Lake is mighty for organizations already using the Spark ecosystem.
Key Features:
- ACID transactions for data lakes
- Time-travel capabilities for data recovery
- Real-time streaming ingestion support
- Native integration with Apache Spark
Best for: Organizations already using the Spark ecosystem
3. Pachyderm – Best for Enterprises
Pachyderm offers enterprise-grade data versioning with Kubernetes-native deployment. It supports any programming language and provides end-to-end pipeline tracking. While the community edition is free, enterprise features require paid licenses starting at custom pricing tiers.
Key Features:
- Kubernetes-native deployment
- Language-agnostic data processing
- End-to-end pipeline tracking
- Enterprise features with custom pricing
Best for: Large enterprises needing scalable data versioning with governance
4. LakeFS – Best for Data Lakes
LakeFS brings Git-like operations to data lakes with zero-copy branching, enabling Write-Audit-Publish workflows that ensure data quality at scale. It’s particularly valuable for large-scale data engineering teams managing petabyte-scale data lakes.
Key Features:
- Zero-copy branching for data lakes
- Git-like operations (branch, commit, merge)
- Write-Audit-Publish workflow support
- Petabyte-scale data management
Best for: Large-scale data engineering teams managing petabyte-scale data lakes
Effective experiment tracking and model management are crucial for maintaining reproducible ML workflows and scaling model development efforts.
Experiment tracking and model management
Why is experiment tracking crucial for ML success? Experiment tracking tools eliminate the chaos of managing hundreds of model training runs, providing centralized visibility into hyperparameters, metrics, model artifacts, and comprehensive metadata management
5. MLflow – Most Popular Open Source
MLflow remains the most popular open-source experiment tracking platform, offering model lifecycle management from tracking to deployment throughout the entire AI development life cycle, supporting the entire process of building an AI model.
It integrates with all major ML frameworks and provides REST APIs for custom integrations, making it compatible with various MLOps frameworks and simplifying the process of integrating AI into an app. MLflow is entirely free as an open-source tool, with managed versions available through cloud providers.
Key Features:
- Comprehensive experiment tracking
- Model packaging and deployment capabilities
- Model registry with versioning
- REST APIs for custom integrations
Pricing: Completely free (open-source), managed versions available
Best for: Teams wanting flexible, framework-agnostic experiment tracking
6. Weights & Biases (W&B) – Best for Enterprises
Weights & Biases offers enterprise-grade experiment tracking with real-time collaboration features, advanced visualization capabilities, and automated hyperparameter sweeps, as well as comprehensive hyperparameter optimization. Their pricing starts at $200/month per team, with a generous free tier for individual users. W&B has become the standard for deep learning teams requiring sophisticated experiment management.
Key Features:
- Real-time experiment collaboration
- Advanced visualization and dashboards
- Automated hyperparameter sweeps
- Model registry and deployment
Pricing: Starts at $200/month per team, generous free tier available
Best for: Deep learning teams requiring sophisticated experiment management
7. Neptune.ai – Best for Foundation Models
Neptune.ai specializes in large-scale experiment tracking, designed to handle foundation model training with fast UI performance and usage-based pricing. It’s particularly popular among research teams working with large language models and complex deep learning architectures.
Key Features:
- Optimized for large-scale experiments
- Fast UI performance with massive datasets
- Advanced metadata tracking
- Usage-based pricing model
Best for: Research teams working with large language models and complex architectures
8. Comet ML – Best All-in-One
Comet ML offers comprehensive experiment tracking with built-in model monitoring capabilities, real-time collaboration features, and an extensive integration ecosystem. Plans start at $149/month, making it accessible for mid-sized teams.
Key Features:
- End-to-end experiment tracking
- Built-in model monitoring
- Real-time collaboration features
- Extensive integration ecosystem
Pricing: Plans start at $149/month.
Best for: Mid-sized teams wanting integrated experiment tracking and monitoring
Feature stores have emerged as critical infrastructure for ensuring consistency between training and production environments.
Feature stores and feature engineering
What problems do feature stores solve? Feature stores solve the challenge of consistent feature engineering across training and serving environments, eliminating the training-serving skew that plagues production ML systems.
9. Feast – Best Open Source
Feast leads the open-source feature store category with its flexible, pluggable architecture supporting both online and offline feature serving. It’s cloud-agnostic and integrates with major data processing frameworks. Feast is completely free and has gained significant traction among teams prioritizing flexibility and control.
Key Features:
- Cloud-agnostic architecture
- Online and offline feature serving
- Integration with major data processing frameworks
- Completely free and open-source
Best for: Teams prioritizing flexibility and avoiding vendor lock-in
10. Tecton – Best for Enterprises
Tecton provides a managed feature platform with enterprise-grade capabilities, real-time feature serving, and comprehensive monitoring. It handles both batch and streaming feature processing with sub-millisecond latency for online serving. Tecton targets enterprise AI customers with complex feature engineering requirements
Key Features:
- Real-time feature serving with sub-millisecond latency
- Batch and streaming feature processing
- Comprehensive monitoring and governance
- Enterprise-grade scalability
Best for: Large enterprises with complex feature engineering requirements
11. Hopsworks Feature Store – Best Hybrid
Hopsworks Feature Store combines open-source flexibility with enterprise features, offering end-to-end feature management with built-in governance and compliance tools. It uses RonDB for high-performance online serving and provides a Python-centric development experience.
Key Features:
- Open-source with enterprise options
- High-performance online serving with RonDB
- Built-in governance and compliance tools
- Python-centric development experience
Best for: Organizations wanting enterprise features with open-source flexibility
12. Databricks Feature Store – Best for Databricks Users
Databricks Feature Store integrates natively with the Databricks platform, offering seamless feature management for teams already using Databricks for analytics and ML. It provides automatic feature discovery and lineage tracking with Delta Lake integration.
Key Features:
- Native Databricks integration
- Automatic feature discovery and lineage tracking
- Delta Lake integration
- Unified analytics and ML platform
Best for: Teams already using Databricks for analytics and ML
Moving from development to production requires robust deployment and serving platforms that can handle real-world demands.
Model deployment and serving platforms
What makes model deployment challenging? Production model deployment requires robust machine learning deployment tools and infrastructure that can handle varying loads, ensure low latency, and provide reliable scaling.
13. Seldon Core – Best Kubernetes-Native
Seldon Core provides Kubernetes-native model deployment with advanced inference graphs supporting A/B testing, canary deployments, and multi-model serving. It integrates with monitoring tools like Prometheus and Grafana for comprehensive model observability and production observability. Seldon Core is an open-source and free-to-use platform.
Key Features:
- Kubernetes-native deployment
- Advanced inference graphs (A/B testing, canary deployments)
- Multi-model serving capabilities
- Integration with Prometheus and Grafana
Best for: Teams using Kubernetes for container orchestration
14. BentoML – Best for Simplicity
BentoML simplifies model packaging, deployment, and model serving capabilities with automatic containerization, API generation, and enterprise containerization support, as well as cloud deployment options for machine learning app development. It supports multiple ML frameworks and provides auto-scaling capabilities. BentoML is open-source, with additional enterprise features available.
Key Features:
- Automatic containerization
- API generation for model serving
- Cloud deployment options
- Auto-scaling capabilities
Best for: Teams wanting simple, fast model deployment
15. Hugging Face Inference Endpoints – Best for NLP
Hugging Face Inference Endpoints specializes in deploying transformer models with enterprise-grade security and auto-scaling. Pricing starts at $0.06/hour for CPU inference and $0.60/hour for GPU inference, making it cost-effective for NLP workloads.
Key Features:
- Optimized for transformer models
- Enterprise-grade security
- Auto-scaling infrastructure
- Cost-effective pricing for NLP workloads
Pricing: Starts at $0.06/hour for CPU inference, $0.60/hour for GPU inference
Best for: NLP workloads using transformer models
16. TensorRT and NVIDIA Triton – Best for Performance
TensorRT and NVIDIA Triton provide high-performance inference servers optimized for NVIDIA GPUs, delivering maximum throughput for deep learning models. They’re particularly valuable for computer vision and large language model deployments.
Key Features:
- Maximum throughput for GPU inference
- Support for multiple frameworks
- Dynamic batching and concurrent execution
- Model ensemble capabilities
Best for: Computer vision and large language model deployments requiring maximum performance
Once models are deployed, continuous monitoring becomes essential to maintain performance and detect issues before they impact business outcomes.
Model monitoring and observability
Why is model monitoring critical? Production model monitoring prevents silent failures and ensures consistent performance as data distributions evolve over time.
17. AI – Best Open Source
Evidently AI offers comprehensive data drift detection and model performance monitoring with interactive dashboards and real-time alerting. It’s completely open-source and provides both cloud and on-premises deployment options.
Key Features:
- Comprehensive drift detection
- Interactive dashboards
- Real-time alerting
- Cloud and on-premises deployment options
Best for: Teams wanting open-source monitoring with professional features
18. WhyLabs – Best for Data Quality
WhyLabs provides AI observability with data quality monitoring, statistical profiling, and drift detection. Their platform offers both free and enterprise tiers, with advanced features for large-scale deployments.
Key Features:
- Statistical data profiling
- Advanced drift detection algorithms
- Data quality monitoring
- Scalable architecture for large deployments
Best for: Large-scale deployments requiring sophisticated data quality monitoring
19. Arize AI – Best for Root Cause Analysis
Arize AI specializes in ML observability with root cause analysis capabilities, bias detection, and performance monitoring. It provides comprehensive dashboards for understanding model behavior in production environments.
Key Features:
- Root cause analysis for model issues
- Bias detection and fairness monitoring
- Performance degradation tracking
- Comprehensive model behavior dashboards
Best for: Teams needing detailed model behavior analysis
20. Fiddler AI – Best for Explainability
Fiddler AI focuses on explainable AI with model monitoring capabilities, offering transparency and compliance features essential for regulated industries. It provides easy-to-understand explanations for model decisions.
Key Features:
- Model explainability and interpretability
- Compliance and governance features
- Bias detection and mitigation
- Regulatory reporting capabilities
Best for: Regulated industries requiring model explainability and compliance
Workflow orchestration ties together all components of the MLOps pipeline, ensuring smooth automation and coordination across different stages.
Workflow orchestration and automation
How do orchestration tools improve MLOps? These ML pipeline orchestration tools automate complex ML pipelines, ensuring reproducibility, reproducible workflows, and efficient resource utilization.
21. Apache Airflow – Most Popular
Airflow remains one of the most popular MLOps tools when it comes to open-source workflow orchestration platforms. Airflow provides Python-based DAG definitions with a rich operator ecosystem. It scales from single-machine deployments to enterprise-grade distributed systems and is completely free.
Key Features:
- Python-based workflow definitions
- Rich operator ecosystem
- Scalable distributed execution
- Comprehensive monitoring and logging
Best for: Teams familiar with Python wanting flexible workflow orchestration
22. Prefect – Best Modern Alternative
Prefect offers modern workflow management and workflow orchestration with hybrid execution models, supporting both cloud and on-premises deployments. It provides intuitive UI, advanced monitoring, and excellent error handling. Prefect offers both open-source and managed cloud versions starting at $39/month.
Key Features:
- Hybrid cloud and on-premises execution
- Intuitive UI and monitoring
- Advanced error handling and recovery
- Dataflow-centric approach
Pricing: Open-source version available, cloud plans start at $39/month
Best for: Teams wanting modern workflow orchestration with better UX than Airflow
23. Kubeflow – Best for ML Pipelines
Kubeflow provides end-to-end ML workflows on Kubernetes, serving as one of the leading machine learning pipeline tools for reproducible model training and deployment. It offers multi-user isolation and integrates with major ML frameworks. Kubeflow is open-source and particularly valuable for teams using Kubernetes.
Key Features:
- Kubernetes-native ML pipelines
- Multi-user isolation
- Integration with major ML frameworks
- Specialized ML components and templates
Best for: Teams using Kubernetes wanting ML-specific pipeline capabilities
24. Dagster – Best for Data Quality
Dagster introduces asset-centric workflow orchestration with strong typing, built-in testing, and comprehensive observability. It’s designed for data engineering teams prioritizing data quality and reliability.
Key Features:
- Asset-centric workflow design
- Strong typing and data validation
- Built-in testing capabilities
- Comprehensive observability and monitoring
Best for: Data engineering teams prioritizing data quality and reliability
The rise of large language models has created new operational challenges requiring specialized LLMOps tools and vector databases.
LLMOps and vector databases
What is LLMOps, and why does it matter? Large Language Model Operations (LLMOps) addresses the unique challenges of deploying and managing foundation models, including prompt management, vector storage, and cost optimization.
25. LangChain – Best Open Source LLMOps
LangChain provides a comprehensive framework for building LLM applications with prompt management, essential for LLM development projects, chain composition, and memory handling. It supports all major LLM providers and offers extensive integration capabilities. LangChain is completely free and has become the standard for LLM application development.
Key Features:
- Comprehensive LLM application framework
- Prompt template management
- Chain composition and memory handling
- Extensive LLM provider integrations
Best for: Developers building custom LLM applications
26. LangSmith – Best for LLM Monitoring
LangSmith provides specialized monitoring and debugging for LLM applications with trace visualization, performance analytics, and prompt optimization. It’s purpose-built for observing and debugging LLM workflows.
Key Features:
- LLM-specific trace visualization
- Prompt performance analytics
- Cost tracking and optimization
- Integration with LangChain ecosystem
Best for: Teams needing comprehensive LLM application monitoring
27. Pinecone – Best Managed Vector Database
Pinecone offers a fully managed vector database optimized for similarity search and retrieval-augmented generation (RAG). It provides high-performance vector search with automatic scaling and enterprise security features.
Key Features:
- Fully managed vector database
- High-performance similarity search
- Automatic scaling and management
- Enterprise security and compliance
Pricing: Starts at $70/month for starter plans.
Best for: Production RAG applications requiring managed infrastructure
28. Chroma – Best Open Source Vector Database
Chroma provides an AI-native embedding database designed for LLM applications. It’s lightweight, easy to use, and integrates seamlessly with popular ML frameworks. Chroma is completely free and open-source.
Key Features:
- AI-native embedding database
- Lightweight and easy deployment
- Integration with ML frameworks
- Completely free and open-source
Best for: Development and prototyping of RAG applications
Managing infrastructure costs is crucial for sustainable MLOps operations, especially as models scale and computational requirements increase.
Cost optimization and resource management
How can teams optimize MLOps costs? Cost optimization tools help manage the expensive infrastructure requirements of ML workloads through smart resource allocation and usage monitoring.
29. Spot.io – Best for Cloud Cost Optimization
Spot.io automatically optimizes cloud costs for ML workloads by intelligently using spot instances and rightsizing resources. It can reduce infrastructure costs by 70-90% while maintaining reliability.
Key Features:
- Automated spot instance management
- ML workload rightsizing
- Cost analytics and reporting
- Multi-cloud support
Best for: Teams with significant cloud infrastructure costs
30. RunPod – Best Serverless GPU Platform
RunPod provides serverless GPU computing with per-second billing, making it cost-effective for intermittent ML workloads. It offers 48% of cold starts under 200ms and supports popular ML frameworks.
Key Features:
- Per-second GPU billing
- Sub-200ms cold starts
- Popular ML framework support
- Global GPU availability
Pricing: Pay-per-use starting at $0.39/hour for RTX 4090.
Best for: Cost-sensitive teams with variable GPU needs
31. Gradient by Paperspace – Best for Managed Notebooks
Gradient provides managed Jupyter notebooks with automatic scaling and cost controls. It offers transparent pricing and integrates with popular MLOps tools.
Key Features:
- Managed Jupyter notebook environment
- Automatic scaling and cost controls
- Integration with MLOps ecosystem
- Transparent usage-based pricing
Best for: Data science teams wanting managed notebook environments
Understanding emerging trends helps organizations stay ahead of the curve and make strategic technology investments.
MLOps Tools Investment Guide: Pricing and ROI Analysis
Understanding MLOps tool pricing is crucial for making informed investment decisions. Here’s a comprehensive breakdown of costs and expected returns:
MLOps tools pricing landscape
MLOps tool pricing varies significantly across categories:
- Open-source solutions: Free (MLflow, DVC, Airflow) but require infrastructure and maintenance costs
- Experiment tracking: $0-200/month per team (W&B, Neptune.ai, Comet ML)
- Feature stores: $500-5,000/month based on usage (Tecton, Hopsworks)
- Model deployment: $0.05-6.00/hour for compute resources (cloud platforms)
- End-to-end platforms: $1,000-10,000+/month (Databricks, SageMaker)
- LLMOps platforms: $50-500/month for small teams, enterprise pricing for large deployments
ROI calculation framework
MLOps investments typically deliver ROI through:
- Reduced time-to-market: 40-60% faster model deployment
- Improved model performance: 15-25% better accuracy through systematic experimentation
- Operational efficiency: 50-70% reduction in manual tasks
- Risk mitigation: Prevention of model failures and compliance violations
- Team productivity: 30-50% increase in data scientist productivity
KEY TAKEAWAY: Most organizations achieve positive ROI within 3-6 months by focusing on high-impact implementations.
Cost-benefit analysis should consider both direct costs (tools, infrastructure, training) and indirect benefits (faster innovation, better model performance, reduced operational risks).
To help you navigate the complex MLOps landscape, here’s a comprehensive comparison of the best tools across each category.
4 Latest MLOps trends and developments in 2025
1. LLMOps and foundation model operations
Large Language Model Operations (LLMOps) has emerged as a specialized discipline within MLOps, addressing unique challenges of deploying foundation models with purpose-built platforms handling the complete LLM lifecycle.
Key LLMOps platforms:
- LangChain: Developer-centric platform for custom LLM pipelines
- LangSmith: Purpose-built for observing and debugging LLM applications
- Weights & Biases: Extended MLOps capabilities with side-by-side LLM evaluation
- Galileo: Performance-focused platform for monitoring NLP output quality
2. Vector databases and retrieval systems
Vector databases have become critical infrastructure for AI applications, particularly RAG systems and semantic search. Leading solutions include Pinecone (cloud-native), Qdrant (open-source), Weaviate (comprehensive platform), and Chroma (AI-native embedding database).
2025 trends include hybrid search combining semantic and keyword capabilities, multi-modal vector storage, and edge databases for reduced latency.
3. Serverless GPU computing revolution
Serverless GPU computing has transformed ML workload management, making high-performance computing accessible without infrastructure overhead. Leading platforms include RunPod (affordability leader), Modal (developer control), Replicate (fast iteration), and Baseten (low-latency inference).
4. AI governance and compliance evolution
Regulatory requirements drive governance-first MLOps approaches. The EU AI Act takes effect in 2026, creating demand for comprehensive MLOps governance workflow tools, including IBM watsonx.governance, Credo AI, and Holistic AI.
MLOps tools implementation roadmap and best practices
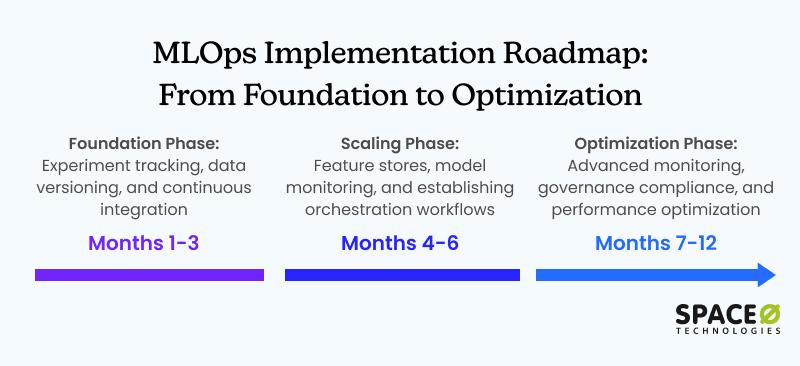
Phase 1: Foundation (Months 1-3)
- Implement experiment tracking (MLflow or W&B)
- Set up data versioning (DVC or Delta Lake)
- Establish basic continuous integration and CI/CD pipelines for MLOps workflows
Phase 2: Scaling (Months 4-6)
- Deploy feature stores (Feast or Tecton)
- Implement model monitoring (Evidently AI or WhyLabs)
- Establish orchestration workflows (Airflow or Prefect)
Phase 3: Optimization (Months 7-12)
- Advanced monitoring and automated retraining
- Governance and compliance frameworks
- Performance optimization and cost management
Success requires starting small, ensuring team adoption, and regularly evaluating tools as needs evolve.
Transform your ML operations with expert guidance
The MLOps landscape in 2025 offers unprecedented opportunities for organizations to scale AI initiatives effectively. With the market projected to grow from $1.7-3.0 billion in 2024 to $39-89 billion by 2034, choosing the right MLOps tools has become critical for competitive advantage.
Key takeaways for MLOps success:
- Start with foundational tools: MLflow, DVC, and Airflow provide excellent beginning points
- Scale gradually: Add specialized tools as requirements and team expertise grow
- Focus on integration: Choose tools that work together and support your existing technology stack
- Prioritize governance: Ensure compliance and monitoring capabilities from the start
- Invest in training: Success depends on team adoption and expertise development
At Space-O Technologies, we’ve successfully implemented MLOps solutions across industries, leveraging our 15+ years of experience in AI software development. Our team of over 140 skilled engineers has delivered more than 300 software solutions, helping 1,200+ clients worldwide achieve their AI for businesses goals with a 98% satisfaction rate
Our MLOps expertise includes:
- Custom platform development using TensorFlow, PyTorch, and cloud-native technologies through our machine learning development services
- End-to-end ML pipeline implementation from data ingestion to model deployment
- Automated retraining systems and compliance frameworks for regulated industries
Ready to transform your ML operations? Contact Space-O Technologies today for a free consultation. Our expert team will assess your requirements, recommend optimal tool combinations, positioning us among the top AI consulting firms for MLOps implementation.
Book your discovery call now and take the first step toward scalable, production-ready ML operations that drive your business forward.
Ready to Streamline Your ML Workflow?
What to read next


