- What Is Named Entity Recognition?
- How NER Models Work: The Five-Step Process
- Common Entity Types That NER Models Recognize
- Types and Approaches in Named Entity Recognition Models
- Top NER Models Compared: Which Should You Choose?
- Key Concepts and Techniques in Named Entity Recognition (NER) Models
- Real-World Applications of NER Models
- Seven Essential Steps for Successful NER Implementation
- Phase 1: Requirements assessment
- 2. Collect and prepare high-quality data
- 3. Annotate entities and build a gold-standard dataset
- 4. Choose the right NER model or framework
- 5. Train, fine-tune, and evaluate the model
- 6. Integrate NER into your workflow and applications
- 7. Monitor, improve, and scale over time
- Build High-Accuracy Named Entity Recognition Models with Space-O AI
- Frequently Asked Questions on Named Entity Recognition Models
Named Entity Recognition Models: A Comprehensive Guide 2026


Named Entity Recognition models play a critical role in how modern NLP systems understand and structure unstructured text. From identifying people, organizations, locations, and dates to extracting domain-specific entities in healthcare, finance, and legal documents, NER models form the backbone of many AI-powered applications. As NLP use cases grow more complex, choosing the right NER model has become just as important as understanding the concept itself.
The NLP market reflects this shift toward advanced language intelligence. According to Markets and Markets, the global natural language processing market is expected to reach USD 68.1 billion by 2028, driven by growing demand for automated text analysis, intelligent search, and AI-powered decision-making. At the core of many of these capabilities lies accurate and scalable Named Entity Recognition.
Over the years, Named Entity Recognition has evolved from rule-based systems and statistical approaches to deep learning and transformer-based models that deliver significantly higher accuracy and scalability.
In this guide, we take a deep dive into Named Entity Recognition (NER) models, explaining how they work, the different types available, and where each model fits best. Get insights from our experience as a leading AI development agency on how popular NER frameworks compare, how to evaluate model performance, and what factors to consider when selecting or building an NER model for real-world NLP applications.
What Is Named Entity Recognition?
Named Entity Recognition, commonly known as NER, is a core natural language processing technique used to identify and classify key entities within unstructured text. These entities typically include names of people, organizations, locations, dates, numerical values, and other domain-specific terms that carry meaningful context in a sentence.
By converting raw text into structured information, NER enables machines to understand who or what is being talked about and how different entities relate to each other. At a functional level, Named Entity Recognition works as a sequence labeling task. The model processes text token by token and assigns a predefined entity label to each word or phrase.
For example, in the sentence “Apple acquired Beats in 2014,” an NER system would identify “Apple” as an organization, “Beats” as an organization, and “2014” as a date. This structured output can then be used by downstream applications for search, analytics, automation, or decision-making.
How NER Models Work: The Five-Step Process
Understanding the mechanics helps you choose the right model for your situation. But to truly grasp the NER meaning, you need to understand how these five steps work together to transform raw text into actionable intelligence. Here’s how NER actually works in practice.
Step 1: Tokenization
The process starts with tokenization, which breaks your raw text into smaller, manageable units. The computer needs to understand where words begin and end, how punctuation works, and what constitutes a meaningful unit.
A sentence like “Dr. Smith works at Johns Hopkins University” gets split into tokens: Dr., Smith, works, at, Johns, Hopkins, University. This sounds simple, but handling abbreviations, punctuation, and special characters correctly is critical for accuracy downstream.
Step 2: Entity identification
Once your text is tokenized, the system identifies potential named entities. It looks at each token and asks: Is this likely part of an entity? This step uses patterns, context from surrounding words, and learned representations to flag candidates. A capitalized word like “Smith” triggers different processing than a lowercase word like “hospital.”
Step 3: Entity classification
After identifying entity candidates, the system classifies what type of entity each one represents. Is “Smith” a person’s name? Is “Johns Hopkins” an organization? This classification step relies on the model’s training. If it learned from examples where “Johns Hopkins” was labeled as an organization, it can recognize similar patterns in new text.
Step 4: Contextual analysis
Context is everything in language. The word “Apple” means something completely different when describing fruit versus when referring to the technology company. This step uses surrounding words and broader context to resolve ambiguity. Modern models use transformer architectures to analyze entire sentences or paragraphs at once, understanding relationships between distant words.
Step 5: Post-processing
Finally, the system refines results through post-processing. It merges multi-token entities (so “Johns Hopkins University” stays together as one entity, not three separate ones), resolves conflicts, and handles edge cases. This step often applies domain-specific rules to improve accuracy in your specific use case.
Many organizations benefit from strategic guidance when evaluating NER options, and they can highly benefit from AI consulting services that can help clarify implementation feasibility.
Common Entity Types That NER Models Recognize
Standard NER systems recognize these predefined entity categories.
- PER (Person): Individual names like Tim Cook, Sarah Johnson, or Dr. Smith.
- ORG (Organization): Company names, institutions, agencies. Examples include Apple, Johns Hopkins University, and the FDA.
- LOC (Location): Geographic references like cities, countries, and regions. New York, California, Europe.
- DATE: Temporal expressions. “Next Tuesday,” “March 15, 2025,” “fiscal year 2024.”
- MONEY: Monetary amounts and currency. “$5 million,” “€200,” “100 pounds.”
- MISC (Miscellaneous): Anything else of interest that doesn’t fit neatly into standard categories. Product names, event names, nationalities.
Different models support different entity types. Some industry-specific models recognize specialized entities like drug names in healthcare or financial instruments in banking. You can also train custom NER models to recognize entity types unique to your business.
Turn NER Models into Production-Ready NLP Solutions
From model selection and fine-tuning to deployment and optimization, Space-O AI brings 15+ years of AI expertise to build reliable and scalable NER systems.
Types and Approaches in Named Entity Recognition Models

Different NER models use different approaches to identify and classify entities. Understanding the main types helps you choose the right model for your needs. Each approach has distinct trade-offs between complexity, accuracy, and scalability.
1. Rule-based NER models
What it is: Rule-based NER relies on manually crafted patterns and predefined dictionaries to identify entities. Capitalized words, specific word order, and company name databases trigger entity classification through conditional logic rules.
How it works: Uses if-then rules based on patterns and dictionaries to identify entities. If a word matches a known company name, it’s classified as an organization.
Strengths: Transparent, auditable, fast to set up.
Limitations: Doesn’t generalize, requires constant manual updates, and doesn’t scale.
2. Machine learning-based NER models
What it is: Machine learning NER learns patterns automatically from labeled training data. Models like SVM, Decision Trees, and CRF analyze features such as capitalization, surrounding words, and grammar to predict entity types without explicit rules.
How it works: Learns patterns from labeled examples and predicts entity types based on learned features. The model studies examples where entities are marked, then recognizes similar patterns in new text.
Strengths: Better generalization than rules, more scalable.
Limitations: Needs substantial labeled data, requires manual feature engineering.
3. Deep learning NER models
What it is: Deep learning NER uses neural networks to automatically learn features from raw text. LSTM and Bidirectional LSTM networks process text sequentially and bidirectionally, capturing complex patterns and long-range dependencies without manual feature engineering.
How it works: Neural networks automatically learn patterns from text data and identify entities. The network analyzes thousands of examples to understand what entity patterns look like.
Strengths: Automatic feature learning, better context understanding.
Limitations: Requires significant training data and GPU resources.
4. Transformer-based NER models (Current standard)
What it is: Transformer-based NER processes entire sentences in parallel using self-attention mechanisms. Pre-trained on massive text corpora, these models learn general language patterns, then fine-tune on specific NER tasks with smaller labeled datasets.
How it works: Pre-trained models process entire text at once using attention, then learn entity patterns from specific examples. The model already understands language from pre-training, so it needs fewer labeled examples to learn your specific entities.
Strengths: Superior accuracy, handles diverse data, and works with smaller datasets.
Limitations: Computationally intensive, slower inference.
The evolution shows a clear trend: as approaches become more sophisticated, they require less manual engineering and achieve better results. Modern NER leverages this progression, with transformer-based models now dominating the field.
With these four approaches in mind, let’s examine the specific NER models and libraries available today that can be deployed in your organization.
Top NER Models Compared: Which Should You Choose?

Choosing the right NER model depends on your specific needs, not on which model is most popular. Different models excel in different scenarios; some prioritize accuracy, others speed. Understanding the strengths and limitations of leading models helps you make an informed decision for your organization.
1. BERT: The foundation model
Best For: Organizations prioritizing accuracy where computational resources are available. Production systems where reliability matters.
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based NER model developed by Google that processes text bidirectionally. Pre-trained on 3.3 billion words across English and Chinese text, BERT learns general language patterns from massive corpora before fine-tuning on specific NER tasks.
It became the foundation for most modern NER models because of its superior performance and became the standard baseline for benchmarking entity recognition systems.
Key features of BERT
- 110 million parameters (base version)
- Pre-trained on massive text corpora
- Bidirectional context understanding
- Works effectively with 1,000-5,000 labeled examples
Strengths of BERT
- Superior accuracy (90.9% F1 on CoNLL-2003 dev set)
- Excellent context understanding
- Well-documented with extensive community support
Limitations of BERT
- Computationally intensive (requires GPU)
- Slower inference speed than traditional models
- High memory requirements
2. RoBERTa
Best For: Teams working in specialized domains like healthcare or finance. Organizations requiring higher accuracy than BERT provides.
RoBERTa (Robustly Optimized BERT) refines BERT’s training using improved pretraining procedures on 160GB of text data. This BERT variant trains on 10x more data than BERT, delivering better generalization to new domains and more robust NER performance across specialized fields.
Key features of RoBERTa
- 125 million parameters (base version)
- More extensive pre-training than BERT
- Better domain transfer performance
- Supports longer documents (1,024 tokens)
Strengths of RoBERTa
- Higher accuracy than BERT
- Better generalization to specialized domains
- Excellent for medical, financial, and legal NER models
Limitations of RoBERTa
- Similar computational requirements to BERT
- Requires GPU infrastructure
- Longer training time
3. DistilBERT
Best For: Real-time applications where speed is critical. Startups with limited computational budgets. High-volume document processing.
DistilBERT is a lightweight version of BERT created through knowledge distillation—a process where a larger model teaches a smaller one. This BERT variant retains 97% of BERT’s performance while reducing model size by 40%, enabling faster inference and lower computational costs without substantial accuracy loss.
Key features of DistilBERT
- 66 million parameters (vs. BERT’s 110M)
- 40% smaller model size
- 60% faster inference
- Runs on consumer GPUs or even CPU
Strengths of DistilBERT
- Fast inference speed
- Can run on modest hardware
- Achieves 92% F1 on CoNLL-2003
- Lower deployment costs
Limitations of DistilBERT
- Slightly lower accuracy than BERT (2-3% drop)
- Less field-tested in specialized domains
- May struggle with domain-specific language
4. spaCy
Best For: Teams prioritizing implementation speed and ease. Production systems where reliability matters. Quick prototyping and deployment.
spaCy is a production-grade NLP library that packages transformer-based NER models into easy-to-use pipelines. The en_core_web_trf model combines transformer-level accuracy with spaCy’s production-focused design, making it ideal for teams who want state-of-the-art entity recognition without complex infrastructure setup.
Key features of spaCy
- Pre-built, production-ready pipelines
- 18 entity types supported
- Integrated with other NLP tasks
- Clean, intuitive Python API
Strengths of spaCy
- Extremely easy to implement (2-3 lines of code)
- Well-designed for production workflows
- Strong performance (89.22% F1 on CoNLL-2003)
- Excellent documentation and community support
Limitations of spaCy
- Less flexible than raw BERT for fine-tuning
- Limited to predefined entity types
- Slightly lower accuracy than dedicated BERT models
5. GLiNER
Best For: Organizations with rapidly changing entity requirements. Teams need extreme flexibility in entity recognition tasks.
GLiNER is a 2024 innovation in NER models that recognizes any entity type without predefined categories. This cutting-edge NER approach uses zero-shot capabilities to extract entities based on natural language descriptions. You describe what to extract in plain language, and it performs named entity recognition without task-specific training.
Key features of GLiNER
- Zero-shot entity recognition (no training required)
- No predefined entity category limits
- Flexible entity extraction from descriptions
- 200M parameter model with bidirectional transformer
Strengths of GLiNER
- Exceptional flexibility; extract any entity type
- No task-specific training required
- Works with emerging entity types easily
- Achieves 60.9% average F1 across multiple zero-shot datasets
Limitations of GLiNER
- Relatively new with less production field testing
- It may be overkill for well-defined entity sets
- Lower accuracy than specialized fine-tuned models
6. Flair
Best For: Research organizations where maximum accuracy is essential. Specialized domains where every percentage point matters. Teams with GPU infrastructure and deep NLP expertise.
Flair is a PyTorch-based NLP library combining different embedding types (word embeddings, character-level representations, transformers). FLERT is Flair’s latest transformer-based NER model, integrating transformer architectures to achieve some of the highest published accuracy scores for NER performance.
Key features of Flair
- Combines multiple embedding approaches
- FLERT model with transformer integration
- Flexible architecture for customization
- Research-oriented and production-capable
Strengths of Flair
- Highest accuracy among open-source options
- Excellent for specialized domains
- Flexible for custom combinations
- Strong performance on domain-specific NER tasks
Limitations of Flair
- Slower inference than BERT or DistilBERT
- More complex to set up than spaCy
- Higher memory requirements
- Steeper learning curve
7. Stanford NER
Best For: Multilingual projects where language coverage is essential. Organizations prefer traditional ML approaches. Legacy systems are already using Stanford tools.
Stanford NER is a mature Java-based tool developed at Stanford University with nearly two decades of production use. This traditional ML-based named entity recognition model uses maximum entropy classifiers with careful feature engineering, providing proven reliability and excellent multilingual NER support across diverse languages.
Key features of Stanford NER
- Supports 25+ languages
- Maximum entropy classifier with CRF options
- Mature, stable codebase
- Java-based with Python wrappers
Strengths of Stanford NER
- Proven reliability over decades
- Excellent multilingual support (25+ languages)
- Well-understood architecture
- Good for traditional ML practitioners
Limitations of Stanford NER
- Lower accuracy than transformer-based approaches (87-90% F1)
- Less active development
- Java dependency complicates deployment
- Slower than neural approaches
8. Google Cloud Natural Language API
Best For: Quick prototyping and experimentation. Organizations already using Google Cloud. One-off NER tasks without scale requirements.
Google’s enterprise-grade NER service accessed via REST API provides real-time entity recognition without requiring you to manage models or infrastructure. This managed NER solution analyzes entities in real time by routing requests through Google’s infrastructure.
Key features of Google Cloud Natural Language API
- REST API for easy integration
- Real-time processing
- Multiple entity types supported
- Multi-language support
Strengths of Google Cloud Natural Language API
- Zero infrastructure management
- Immediate results (no training)
- Simple integration
- Reliable cloud-based service
Limitations of Google Cloud Natural Language API
- Lower accuracy than state-of-the-art models (85-90% F1)
- Per-request pricing (not cost-effective at scale)
- Limited customization
- Data sent to Google servers (privacy considerations)
9. AWS Comprehend
Best For: Organizations already using AWS. Large-scale batch document processing. Teams with custom entity requirements and sufficient training data.
AWS’s managed entity recognition service provides NER capabilities through simple API calls. This fully managed NER solution works on documents in S3 or provided directly, enabling entity extraction without infrastructure overhead or model management.
Key features of AWS Comprehend
- Fully managed service with no infrastructure needed
- Batch processing for large document volumes
- Integration with S3 and AWS services
- Custom entity types through training
- Multi-language support
Strengths of AWS Comprehend
- Zero infrastructure management
- Good integration with the AWS ecosystem
- Batch processing is cost-effective for large volumes
- Custom training available for specialized NER models
Limitations of AWS Comprehend
- Lower accuracy than state-of-the-art models (85-90% F1)
- Custom training requires significant labeled data
- Pricing can be expensive for unpredictable volumes
- AWS ecosystem dependency
10. IBM Watson Natural Language Understanding
Best For: Enterprise organizations with IBM infrastructure. Teams require comprehensive NLP beyond just entity recognition. Organizations with dedicated NLP budgets.
IBM’s enterprise NLP platform provides entity extraction as part of its comprehensive NLP capabilities. This managed NER solution is particularly popular in organizations already using IBM infrastructure, combining entity recognition with advanced sentiment analysis and other NLP features.
Key features of IBM Watson Natural Language Understanding
- Enterprise-grade reliability
- Advanced sentiment analysis alongside NER
- Multiple entity types supported
- IBM Cloud integration
- Professional support available
Strengths of IBM Watson Natural Language Understanding
- Enterprise reliability and support
- Comprehensive NLP capabilities beyond NER
- Professional support included
- Good for IBM ecosystem organizations
Limitations of IBM Watson Natural Language Understanding
- Higher costs than cloud competitors (85-90% F1 accuracy)
- IBM ecosystem dependency
- Less flexible than open-source approaches
- Slower innovation compared to research models
How to choose the right NER model for your solution
The right model depends on what matters most for your use case:
- Accuracy first? → Flair or RoBERTa
- Speed critical? → DistilBERT or spaCy
- Flexibility needed? → GLiNER
- Simplicity? → spaCy or Google Cloud
- Multilingual? → Stanford NER or multilingual BERT
- Enterprise support? → AWS, Google Cloud, or IBM Watson
Start by identifying your primary constraint, then the model choice becomes clear. For complex selection decisions, many teams hire AI consultants who can assess your specific requirements and recommend the optimal approach.
Understanding the models is just the beginning. To truly leverage NER effectively, you need to grasp the fundamental concepts and techniques that power these systems, from tokenization to attention mechanisms to fine-tuning strategies.
Struggling with NER Accuracy or Model Performance?
Space-O AI provides expert guidance on data annotation, model architecture, and transformer fine-tuning to improve Named Entity Recognition outcomes.
Key Concepts and Techniques in Named Entity Recognition (NER) Models

Every NER model makes critical decisions behind the scenes, from how it splits text into tokens to how it focuses on relevant context. The difference between a 70% accurate entity recognition system and a 90% accurate one often comes down to mastering these foundational techniques. This section explores the core concepts that determine whether your NER implementation succeeds or struggles in production.
1. Tokenization
Tokenization is the process of breaking text into smaller, model-friendly units called tokens.
- Word-level tokenization splits text based on spaces, but struggles with unseen or rare words (“microfinance”, “immunomodulatory”).
- Subword tokenization (BPE, WordPiece, SentencePiece) splits words into meaningful fragments like immuno + modulatory so the model can handle variations, typos, and rare entities. Because modern transformer-based NER models rely on subword units, tokenization directly affects how accurately entities are detected.
2. Word Embeddings
Embeddings transform words into numerical vectors that encode their meaning.
- Static embeddings like Word2Vec and GloVe always assign the same vector to a word, even if used differently (e.g., “Apple” fruit vs. “Apple” company).
- Contextual embeddings (ELMo, BERT, RoBERTa) generate representations based on surrounding words, letting the model understand nuance. This shift to context-aware embeddings is one of the biggest reasons modern NER models achieve high accuracy and resolve ambiguities effectively.
3. Self-Attention Mechanisms
Self-attention allows a model to look at all tokens in a sentence at once and determine which ones influence each other. For example, in “Apple released its earnings…”, the model assigns high attention between “Apple” and “released”, signaling it’s a company, not a fruit.
Multi-head attention multiplies this ability by running multiple attention calculations in parallel, each head learns different types of relationships (syntax, coreference, meaning). This mechanism is the core of why transformers outperform older architectures in NER.
4. Sequence Labeling and BIO Tagging
NER is a token-level prediction task, so models label each token with a tag representing whether it’s part of an entity.
The most common tagging format is BIO:
- B – beginning of an entity
- I – inside the entity
- O – outside any entity
To improve tag consistency, many NER models add a Conditional Random Field (CRF) layer on top of model predictions. The CRF ensures valid sequences (e.g., an “I-ORG” tag cannot follow an “O” tag unless preceded by “B-ORG”), which significantly boosts accuracy.
5. Contextual Encoding
Contextual encoding refers to how models capture the meaning of a token based on its surrounding words. Older architectures like BiLSTMs read text left-to-right and right-to-left, combining both directions to infer context.
Transformers, however, use self-attention to process the entire sequence in parallel, allowing them to capture long-range dependencies more efficiently. This architectural improvement is why transformer-based NER models consistently outperform RNN-based ones.
6. Training Datasets and Benchmarks
The strength of an NER model heavily depends on the quality and domain of the training data.
- CoNLL-2003 is the most widely used English benchmark, and top transformer models achieve around ~89% F1 score.
- OntoNotes offers broader categories and more diverse sources.
- WikiANN supports multilingual NER across hundreds of languages.
- Domain-specific datasets exist for biomedical, legal, clinical, financial, and cybersecurity NER tasks. Selecting the right dataset is crucial because NER models learn patterns that are highly domain-dependent.
For specialized domain datasets, many teams hire AI developers who have experience building and curating training data for their specific industry requirements.
Understanding the technical foundations of NER models is valuable only when applied to solve real business problems. Across industries, organizations use named entity recognition to transform unstructured text into actionable intelligence, automating tasks that once required manual processing and enabling decision-making at scale.
Let’s explore how different sectors leverage NER to drive measurable business value.
Real-World Applications of NER Models
Named Entity Recognition has become one of the most widely adopted NLP techniques because it turns unstructured text into structured, machine-readable insights. From compliance automation to customer analytics, NER powers dozens of real-world use cases across industries. Below are the most impactful applications.
1. Healthcare and medical records
What NER Extracts: Patient names, medical conditions, drug names, dosages, treatment procedures, lab test results, and medical facilities.
How It’s Used: Extract and organize patient information from clinical notes to automatically identify medical conditions, flag drug interactions, and match patients to clinical trials.
Business Impact: It accelerates diagnosis by providing clinicians with relevant historical context and reduces medication errors through automated drug-interaction flagging. It also improves clinical trial enrollment by identifying eligible patients faster and eliminates the manual data entry burden.
These specialized healthcare applications often require teams to partner with an AI healthcare software development company with domain expertise in medical entity recognition and HIPAA compliance.
2. Finance and banking
What NER Extracts: Company names, monetary values, dates, financial instruments, stock symbols, regulatory references, market events.
How It’s Used: Monitor news and financial documents for company mentions, track market-moving events, detect fraud through suspicious entity patterns, and flag regulatory compliance issues automatically.
Business Impact: Faster trading decisions based on real-time news analysis, reduced fraud losses through automated suspicious pattern detection, improved regulatory reporting accuracy, and decreased manual compliance monitoring costs.
3. Customer service and chatbots
What NER Extracts: Product names, customer names, complaint types, technical issues, sentiment triggers, service references.
How It’s Used: Understand customer queries by identifying products and issues mentioned, automatically route tickets to relevant teams, and personalize responses based on extracted information.
Business Impact: It enables faster customer issue resolution through intelligent routing and reduces support team workload by automating routine queries. It also improves customer satisfaction with context-aware responses while providing 24/7 service availability without proportional staffing increases.
4. E-commerce and retail
What NER Extracts: Product names, brand names, features, pricing mentions, competitor references, customer sentiment triggers.
How It’s Used: Extract product features and sentiment from customer reviews to identify what customers like and dislike, power personalized recommendations, and track competitor mentions.
Business Impact: It enables data-driven product improvements based on real customer feedback and increases conversion rates through personalized recommendations. It also helps optimize inventory to match actual customer preferences and provides a competitive advantage through early trend detection.
5. Legal document analysis
What NER Extracts: Parties to contracts, dates, monetary terms, obligations, legal references, clauses, and regulatory requirements.
How It’s Used: Automatically extract key contract terms, identify non-standard clauses, check for missing legal requirements, and flag compliance issues in legal documents.
Business Impact: It reduces document review time from days to hours and speeds up mergers and acquisitions through accelerated due diligence. It also lowers legal risk through systematic compliance checking and reduces legal costs by automating routine document review.
6. Human resources and recruitment
What NER Extracts: Job titles, skills, certifications, educational qualifications, years of experience, company names, and technical competencies.
How It’s Used: Parse resumes to extract skills and qualifications automatically, match candidates to job requirements, and screen out unqualified applicants before manual review.
Business Impact: It significantly reduces time-to-hire through automated screening and improves candidate quality through systematic skill matching. It also lowers hiring costs by automating early review stages and enables more objective candidate evaluation by removing human bias from initial screening.
Looking to Build Domain-Specific Named Entity Recognition Models?
Space-O AI helps you develop custom NER models that handle real-world data complexity and domain-specific entities.
Seven Essential Steps for Successful NER Implementation
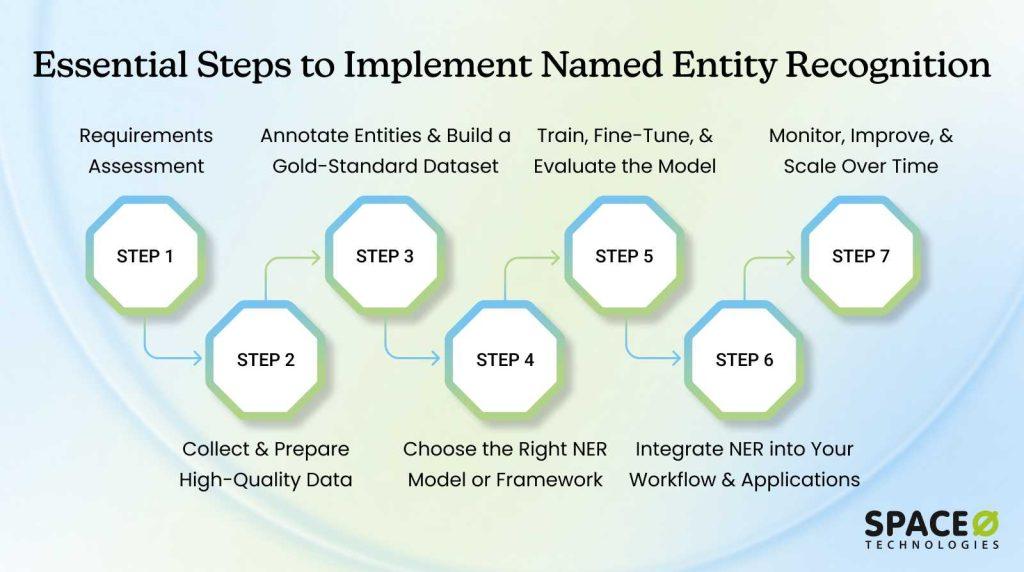
Named Entity Recognition implementation moves through seven clear phases: assessment, data preparation, model selection, development, production deployment, monitoring, and optimization. Each phase builds on the previous, with critical decision points determining your overall success and timeline.
Phase 1: Requirements assessment
Successful NER implementation starts with clarity on what you want to extract and how those entities will support business goals. Whether the goal is automating document processing, improving search relevance, enriching analytics, or powering downstream AI tasks, well-defined objectives help shape data requirements, model selection, and performance expectations.
Action items
- Identify target entity types and their business value
- Map NER outputs to specific workflows or products
- Define measurable goals and KPIs (accuracy, coverage, speed)
- List priority use cases and edge cases
2. Collect and prepare high-quality data
High-quality, domain-relevant text is the foundation of any reliable NER system. This involves gathering representative samples from real business sources and preparing them by removing noise, standardizing formats, and ensuring consistency. Good data diversity leads to better model generalization.
Action items
- Gather text from relevant sources (emails, tickets, clinical notes, reports, etc.)
- Clean and normalize raw text for consistency
- Remove duplicates, noise, and irrelevant sections
- Ensure data covers common scenarios and exceptions
3. Annotate entities and build a gold-standard dataset
Annotation transforms raw text into labeled training data, turning sentences into structured examples that models can learn from. Consistent, high-quality annotations are crucial, especially for specialized domains. Clear guidelines and quality checks ensure your “ground truth” dataset remains reliable.
Action items
- Define entity categories and annotation rules
- Use annotation tools like Prodigy, Label Studio, or LightTag
- Train annotators and check inter-annotator agreement
- Build a curated, high-quality labeled dataset
4. Choose the right NER model or framework
Selecting the appropriate model depends on your domain complexity, performance needs, and infrastructure constraints. Pre-trained transformers often deliver the best accuracy, while rule-based or hybrid systems work well for highly regulated or deterministic use cases.
Action items
- Evaluate transformer models (BERT, RoBERTa, domain-specific variants)
- Consider productive frameworks like spaCy or Hugging Face
- Assess whether rule-based or hybrid approaches are needed
- Choose models based on accuracy, speed, and scalability
5. Train, fine-tune, and evaluate the model
Training involves fine-tuning the model on your annotated dataset and validating performance using standard metrics. This step helps uncover weaknesses, such as misclassified entities or boundary errors, and ensures the model performs reliably before deployment.
Action items:
- Split the dataset into training, validation, and test sets
- Fine-tune the model using domain-specific data
- Evaluate using precision, recall, and F1-score
- Analyze error patterns and optimize hyperparameters
6. Integrate NER into your workflow and applications
After achieving the desired accuracy, the model must be embedded into real business workflows. Integrating NER with internal tools, APIs, or downstream analytics converts extracted entities into meaningful business outcomes and automations.
Action items
- Deploy the model into production or API endpoints
- Connect NER output to dashboards, search, or automation tools
- Integrate with existing systems (CRM, EMR, ticketing, CMS)
- Design clear data flows for downstream processing
Integration complexity often requires specialized support; many organizations opt for AI integration services to connect NER systems with existing infrastructure, ensuring reliable API connections and data flow integrity.
7. Monitor, improve, and scale over time
NER systems evolve alongside your data. Continuous monitoring ensures accuracy remains high as new terminology, formats, or user behaviors emerge. Regular retraining with fresh data and performance optimizations helps the system stay reliable and scalable.
Action items
- Track accuracy and error rates in production
- Collect new examples for periodic retraining
- Update entity definitions as business needs evolve
- Scale infrastructure to support growing usage
While NER technology is mature, implementing it successfully in production requires navigating real-world obstacles. The challenges below represent patterns from dozens of implementations across industries. Each is solvable, but requires specific strategies and planning.
Need Help Implementing Named Entity Recognition Models?
Leverage 15+ years of AI development experience and 500+ AI solutions delivered to design, train, and deploy NER models tailored to your data, domain, and performance goals.
Build High-Accuracy Named Entity Recognition Models with Space-O AI
Named Entity Recognition models are no longer optional for advanced NLP systems. They play a critical role in extracting structured intelligence from unstructured text and directly impact the accuracy of applications such as document processing, search, conversational AI, and analytics. However, implementing NER models that perform reliably in real-world scenarios requires more than selecting a popular architecture or pre-trained model.
Successful NER implementation demands strong technical expertise across data preparation, domain-specific annotation, model selection, fine-tuning, and performance evaluation. Teams must also address challenges related to ambiguity, scalability, inference latency, and long-term model maintenance. Without the right expertise, NER models can struggle to deliver consistent accuracy or adapt to evolving business requirements.
This is where an experienced AI development partner becomes essential. Space-O AI helps businesses design, build, and deploy NER-based solutions tailored to specific domains and use cases. With 15+ years of AI engineering experience and 500+ AI solutions developed, we build custom Named Entity Recognition models that align with real-world data, accuracy expectations, and deployment constraints.
From building domain-specific NER pipelines to fine-tuning transformer models and integrating them into production systems, Space-O AI supports the entire development lifecycle.
If you are planning to implement Named Entity Recognition models or enhance existing NLP capabilities, partnering with the right AI experts can significantly reduce risk and accelerate outcomes. Talk to our experts today to discuss your NER requirements and explore how our AI development expertise can help you build scalable, high-performing NLP solutions.
Frequently Asked Questions on Named Entity Recognition Models
1. What’s the difference between NER models?
Rule-based NER models use manual rules for simple patterns. Machine learning NER models balance accuracy with moderate data needs. Transformer-based NER models like BERT achieve the highest accuracy but require more training data.
LLM-based named entity recognition models offer flexibility without retraining. Your choice depends on accuracy requirements, available data, and computational resources for training your specific NER implementation.
2. How much do custom named entity recognition models cost?
Simple named entity recognition projects cost $30K–50K with straightforward entities. Medium complexity with annotation ranges $100K–250K. Enterprise NER systems reach $250K+. Major costs include data annotation ($15–40k), GPU training compute, and production infrastructure.
Budget for development and ongoing operations when planning custom NER implementation. Costs vary based on entity complexity, data volume, and accuracy requirements for your named entity recognition system.
3. When should we build custom NER vs. use pre-built APIs?
Test pre-built named entity recognition solutions first on your data. Build custom named entity recognition models only if pre-built APIs underperform by over ten percent. Custom NER makes sense for specialized entity types, strict data privacy, or long-term cost savings at scale.
Pre-built NER solutions suit general use cases needing faster deployment. Choose between custom NER and APIs based on accuracy needs, privacy requirements, and timeline for your specific named entity recognition project.
4. What training data do we need for NER models?
Rule-based NER systems need pattern definitions only. Machine learning NER models require three hundred to five hundred labeled examples. Transformer-based NER models work better with eight hundred plus examples.
Transfer learning from pre-trained NER models reduces data requirements significantly. Quality matters most for named entity recognition training data. Well-annotated, consistent data outperforms large, inconsistent datasets for your NER implementation success and accuracy.
5. Can NER work across multiple languages?
Multilingual named entity recognition models like mBERT support over one hundred languages simultaneously, with lower accuracy than language-specific options. For strict accuracy, train separate NER models per critical language with one hundred to two hundred examples each. Language-specific NER models typically outperform multilingual versions.
Choose your approach based on accuracy requirements and maintenance resources available for your multilingual named entity recognition implementation.
Need Expert Help with NER Development?
What to read next


